Czym jest RAG i jak wpływa na rozwój AI

W dynamicznie rozwijającym się świecie sztucznej inteligencji pojawiają się technologie, które znacząco zmieniają sposób interakcji z informacją. Jedną z nich jest RAG, czyli Retrieval-Augmented Generation. To innowacyjne podejście łączy moc dużych modeli językowych (LLM) ze zdolnością do wyszukiwania informacji w zewnętrznych bazach danych, co prowadzi do generowania odpowiedzi bardziej trafnych, aktualnych i wiarygodnych. Zrozumienie, co to jest RAG, staje się kluczowe dla firm i deweloperów pragnących wykorzystać pełny potencjał AI. Widocznym przykładem tego trendu, obrazującym potrzebę łączenia generowania z wyszukiwaniem, są funkcje takie jak AI Overviews w wyszukiwarce Google, która stara się dostarczać syntetyczne odpowiedzi na zapytania użytkowników, czerpiąc informacje z wielu źródeł – co jest ideą bliską założeniom RAG.
Co to jest RAG (Retrieval-Augmented Generation)? Definicja i kluczowe założenia
RAG, czyli Retrieval-Augmented Generation, to architektura AI, która udoskonala działanie dużych modeli językowych (LLM) poprzez dynamiczne integrowanie informacji z zewnętrznych źródeł wiedzy przed wygenerowaniem odpowiedzi. Zamiast polegać wyłącznie na wewnętrznej, często statycznej wiedzy zakodowanej podczas treningu, model RAG najpierw wyszukuje (retrieval) relewantne fragmenty informacji z określonego korpusu danych (np. bazy dokumentów firmowych, artykułów naukowych, aktualnych wiadomości czy, jak w przypadku AI Overviews, z zaindeksowanych stron internetowych, a następnie wykorzystuje te fragmenty jako dodatkowy kontekst do wygenerowania (generation) bardziej precyzyjnej i opartej na faktach odpowiedzi. Wyjaśnienie pojęcia RAG w języku polskim można sprowadzić do koncepcji „generowania wspomaganego wyszukiwaniem”.
Podstawowym problemem, który RAG stara się rozwiązać, są tak zwane halucynacje AI – tendencja LLM do generowania odpowiedzi, które brzmią wiarygodnie, ale są nieprawdziwe lub nie mają pokrycia w faktach. RAG minimalizuje to ryzyko, „uziemiając” odpowiedzi modelu w konkretnych, sprawdzalnych danych pochodzących z zaufanego źródła. Dzięki temu odpowiedzi są nie tylko bardziej dokładne, ale mogą być również bardziej aktualne niż wiedza zamrożona w czasie podczas ostatniego treningu LLM.
Jak działa RAG? Mechanizm krok po kroku
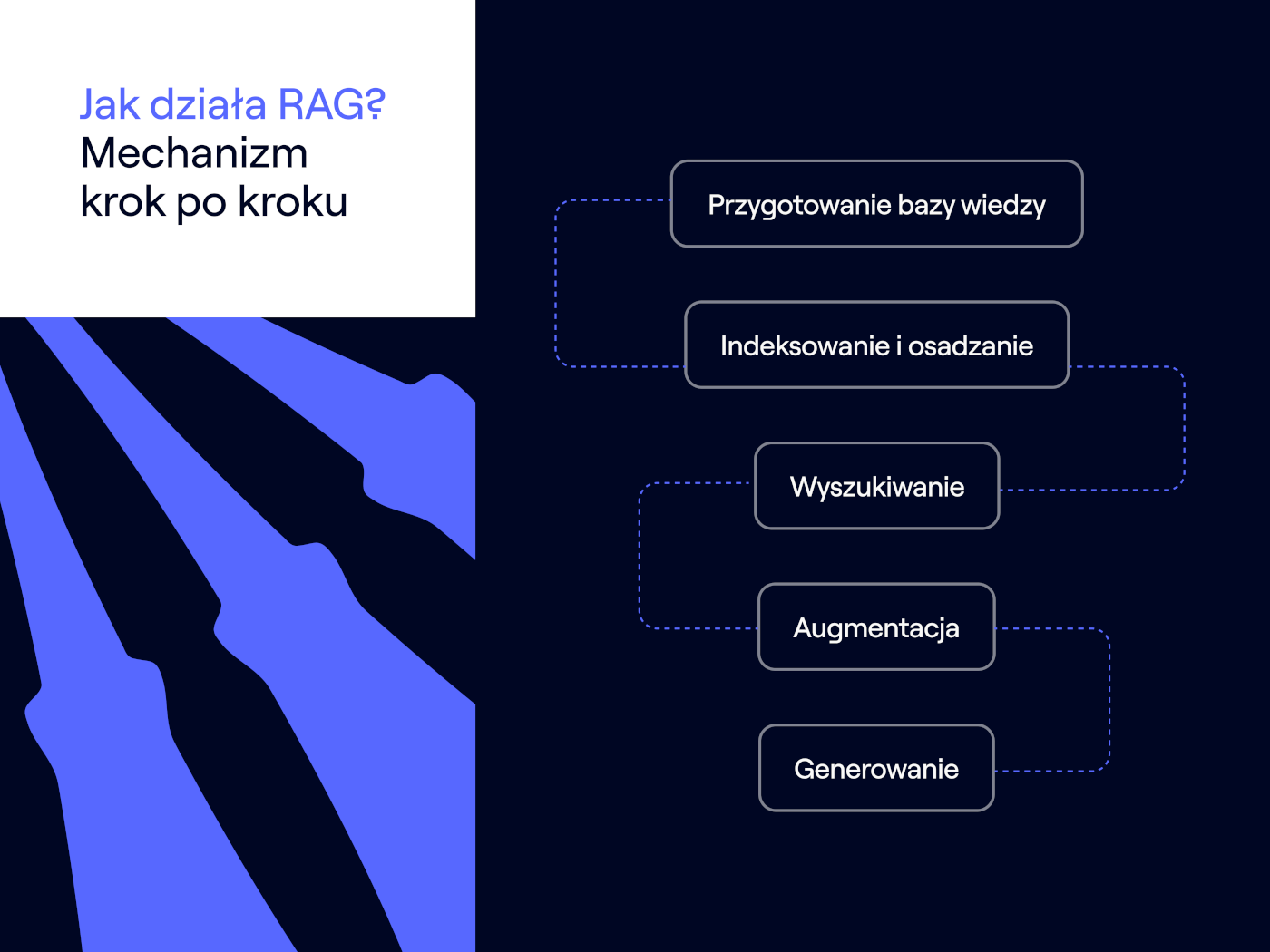
Proces działania systemu RAG (Retrieval-Augmented Generation) można podzielić na kilka kluczowych etapów, które razem tworzą spójny mechanizm dostarczania informacji:
- Przygotowanie bazy wiedzy – na początku konieczne jest zgromadzenie i przetworzenie danych, które będą stanowiły zewnętrzne źródło informacji. Dokumenty (np. PDF, strony internetowe, wpisy w bazie danych) są dzielone na mniejsze fragmenty (chunks).
- Indeksowanie i osadzanie (Embedding) – każdy fragment tekstu jest przekształcany w wektor numeryczny za pomocą specjalnego modelu osadzania (embedding model). Wektory te reprezentują semantyczne znaczenie tekstu. Następnie są one przechowywane i indeksowane w specjalnej bazie danych wektorowych, która umożliwia szybkie i efektywne wyszukiwanie podobnych semantycznie fragmentów.
- Wyszukiwanie (Retrieval) – gdy użytkownik zadaje pytanie (prompt), jest ono również przekształcane na wektor za pomocą tego samego modelu osadzania. Następnie system (tzw. retriever) przeszukuje bazę wektorową, aby znaleźć fragmenty tekstu (kontekst), których wektory są najbardziej podobne do wektora zapytania. Wykorzystuje się tu miary podobieństwa, takie jak podobieństwo kosinusowe. W systemach takich jak AI Overviews, ten etap polega na wyszukaniu relewantnych informacji na zaindeksowanych stronach internetowych.Zobacz również
- Augmentacja (Augmentation) – znalezione, najbardziej relewantne fragmenty tekstu są łączone z oryginalnym zapytaniem użytkownika. Tworzy to rozszerzony prompt, który zawiera zarówno pytanie, jak i dodatkowy, dynamicznie pobrany kontekst.
- Generowanie (Generation) – rozszerzony prompt jest przekazywany do dużego modelu językowego (LLM), czyli generatora. LLM, mając do dyspozycji zarówno oryginalne pytanie, jak i kontekst z wyszukanych dokumentów, generuje odpowiedź. Dzięki temu odpowiedź jest oparta na dostarczonych, potencjalnie aktualnych i specyficznych danych, a nie tylko na ogólnej wiedzy modelu. Implementacja AI RAG (Retrieval-Augmented Generation) w ten sposób znacząco poprawia jakość odpowiedzi.

Kluczowe komponenty systemu RAG
Aby system RAG mógł efektywnie funkcjonować, wymaga współdziałania kilku kluczowych komponentów:
- Baza wiedzy (Knowledge Base) – zbiór dokumentów i danych, które stanowią zewnętrzne źródło informacji. Może to być wewnętrzna baza danych firmy, zbiór artykułów naukowych, dokumentacja techniczna, strony internetowe itp. W przypadku systemów publicznych jak AI Overviews, bazą wiedzy jest de facto ogromny, dynamiczny zbiór zaindeksowanych treści internetowych. Jakość i aktualność tej bazy są kluczowe dla skuteczności całego systemu.
- Model osadzania (Embedding Model) – algorytm (najczęściej sieć neuronowa) odpowiedzialny za przekształcanie fragmentów tekstu oraz zapytań użytkownika w wektory numeryczne (osadzenia). Jakość modelu osadzania wpływa na trafność wyszukiwania semantycznego.
- Wektorowa baza danych (Vector Database) – specjalistyczna baza danych zoptymalizowana pod kątem przechowywania i szybkiego przeszukiwania dużych zbiorów wektorów numerycznych na podstawie podobieństwa. Przykłady to Pinecone, Weaviate, Milvus czy Chroma. W skali internetu, mechanizmy indeksowania i wyszukiwania są znacznie bardziej złożone.
- Retriever – komponent odpowiedzialny za przyjęcie zapytania użytkownika (przekształconego na wektor), przeszukanie wektorowej bazy danych i zwrócenie najbardziej relewantnych fragmentów tekstu (kontekstu).
- Duży Model Językowy (LLM – Generator) – model AI (np. z rodziny GPT, Llama, Claude) odpowiedzialny za wygenerowanie finalnej odpowiedzi na podstawie oryginalnego zapytania i dostarczonego przez retrievera kontekstu.
Korzyści z wykorzystania technologii RAG
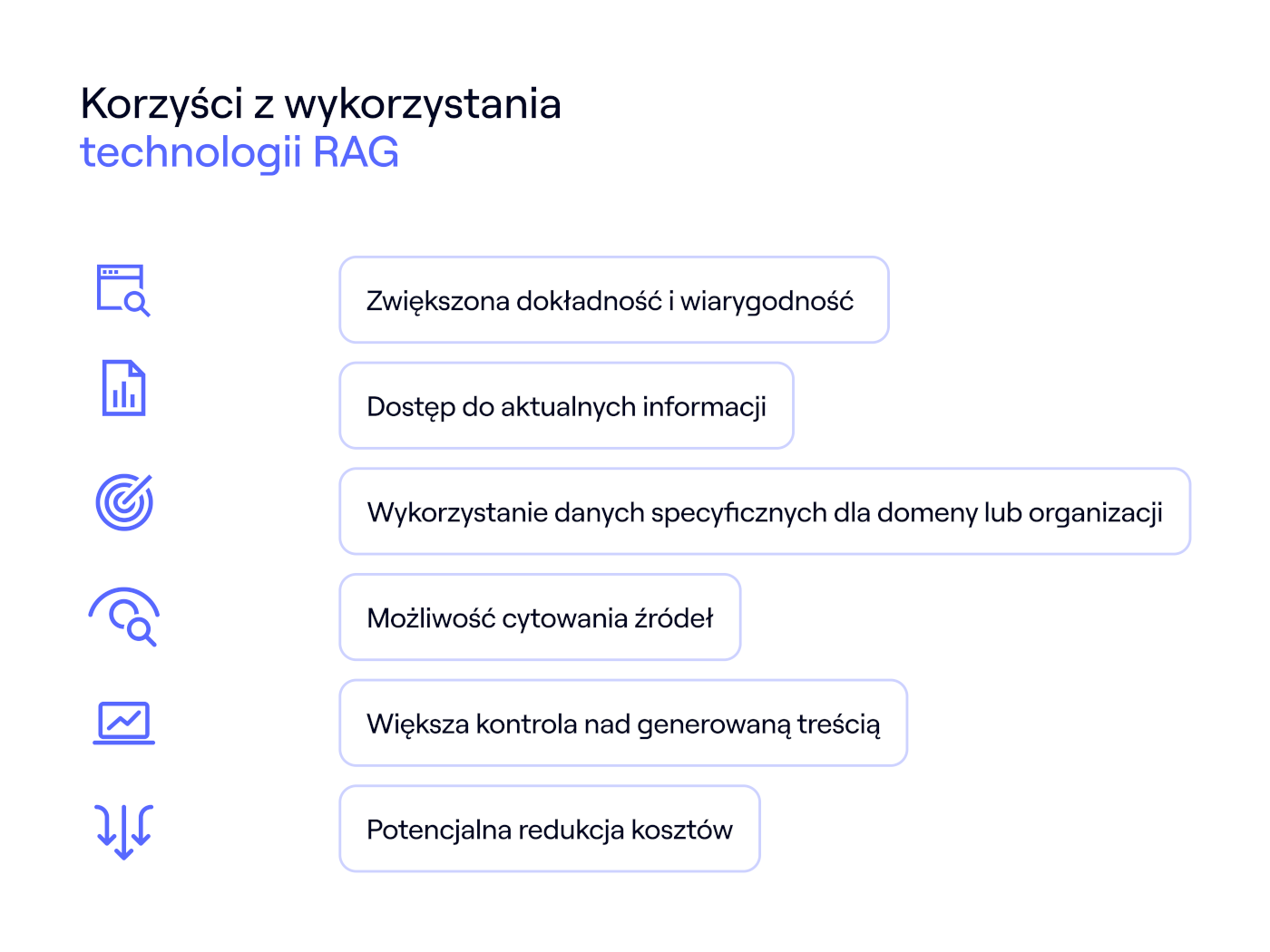
Implementacja technologii RAG przynosi szereg wymiernych korzyści, które czynią ją atrakcyjnym rozwiązaniem w wielu zastosowaniach AI:
- Zwiększona dokładność i wiarygodność – odpowiedzi generowane przez system RAG są oparte na konkretnych danych z zewnętrznej bazy wiedzy, co znacząco redukuje ryzyko generowania nieprawdziwych informacji (halucynacji) i zwiększa zaufanie do wyników.
- Dostęp do aktualnych informacji – w przeciwieństwie do standardowych LLM, których wiedza jest ograniczona do momentu zakończenia treningu, RAG może korzystać z na bieżąco aktualizowanych baz danych, zapewniając dostęp do najnowszych informacji.
- Wykorzystanie danych specyficznych dla domeny lub organizacji – RAG umożliwia „karmienie” LLM wiedzą specyficzną dla danej branży, firmy czy projektu (np. wewnętrznymi regulaminami, dokumentacją techniczną, bazą klientów), co pozwala na generowanie odpowiedzi niedostępnych dla modeli ogólnego przeznaczenia.
- Możliwość cytowania źródeł – ponieważ odpowiedź jest generowana na podstawie konkretnych fragmentów z bazy wiedzy, system RAG może wskazać źródła, na których się oparł, co zwiększa transparentność i pozwala użytkownikowi na weryfikację informacji.
- Większa kontrola nad generowaną treścią – poprzez zarządzanie zawartością bazy wiedzy, organizacje mają większą kontrolę nad tym, jakie informacje są wykorzystywane przez model do generowania odpowiedzi.
- Potencjalna redukcja kosztów – aktualizacja wiedzy w RAG odbywa się poprzez modyfikację bazy wiedzy, co jest zazwyczaj znacznie tańsze i szybsze niż kosztowne i czasochłonne ponowne trenowanie lub fine-tuning dużego modelu językowego.
RAG vs fine-tuning – kiedy wybrać które podejście?
Zarówno RAG, jak i fine-tuning (dostrajanie) LLM są technikami służącymi do adaptacji modeli językowych do specyficznych zadań lub dziedzin wiedzy, jednak działają na różnych zasadach i sprawdzają się w innych sytuacjach.
Fine-tuning polega na dodatkowym treningu wstępnie wytrenowanego LLM na mniejszym, specyficznym zbiorze danych. Proces ten modyfikuje wewnętrzne parametry (wagi) modelu, aby „nauczyć” go nowego stylu, specyficznej terminologii lub konkretnych wzorców odpowiedzi. Jest to skuteczne, gdy chcemy zmienić zachowanie modelu, jego tonację lub nauczyć go specyficznych umiejętności, które nie wymagają dostępu do rozległej, dynamicznie zmieniającej się wiedzy.
RAG natomiast nie modyfikuje samego LLM, lecz dostarcza mu zewnętrzną wiedzę „na żądanie” w momencie generowania odpowiedzi. Jest to idealne rozwiązanie, gdy kluczowy jest dostęp do aktualnych lub bardzo specyficznych, obszernych zbiorów danych, których nie dałoby się efektywnie „wkomponować” w model podczas fine-tuningu. RAG sprawdza się doskonale w systemach Q&A opartych na dokumentach, chatbotach korzystających z wewnętrznej bazy wiedzy firmy czy narzędziach wymagających dostępu do najnowszych informacji – idea ta leży u podstaw działania funkcji typu AI Overviews, które muszą czerpać z aktualnych zasobów sieci.
Wybór między RAG a fine-tuningiem zależy od konkretnego celu:
- Wybierz RAG, gdy – potrzebujesz dostępu do aktualnej lub specyficznej wiedzy zewnętrznej, chcesz zminimalizować halucynacje, potrzebujesz cytowania źródeł, dysponujesz dużą bazą dokumentów.
- Wybierz Fine-tuning, gdy – chcesz nauczyć model nowego stylu, tonu, formatu odpowiedzi, chcesz zaadaptować go do specyficznego zadania niekoniecznie wymagającego wiedzy zewnętrznej (np. klasyfikacja tekstu, podsumowanie w określonym stylu).
Warto również zauważyć, że obie techniki mogą być stosowane łącznie. Można np. najpierw dostroić model (fine-tuning), aby lepiej rozumiał specyfikę danej dziedziny, a następnie zintegrować go z systemem RAG, aby zapewnić mu dostęp do aktualnych danych z tej dziedziny.
Wyzwania i ograniczenia technologii RAG
Mimo licznych zalet, technologia RAG wiąże się również z pewnymi wyzwaniami i ograniczeniami, które należy wziąć pod uwagę podczas jej wdrażania:
- Jakość bazy wiedzy – zasada „garbage in, garbage out” ma tu kluczowe znaczenie. Jeśli baza wiedzy zawiera nieaktualne, niekompletne lub błędne informacje, system RAG będzie generował odpowiedzi niskiej jakości. Wymaga to starannego przygotowania, czyszczenia i regularnej aktualizacji danych. Publiczne przykłady, takie jak niekiedy kontrowersyjne lub błędne wyniki generowane przez AI Overviews, pokazują, jak krytyczna jest jakość i odpowiednia interpretacja danych źródłowych (w tym przypadku – internetu, który zawiera treści o różnej wiarygodności).
- Skuteczność retrievera – zdolność do znalezienia naprawdę relewantnych fragmentów tekstu jest kluczowa. Niewłaściwie dobrane fragmenty (nawet jeśli poprawne merytorycznie) mogą wprowadzić LLM w błąd lub prowadzić do odpowiedzi nie na temat. Optymalizacja procesu retrievalu (np. dobór wielkości fragmentów, wybór modelu osadzania, strategia wyszukiwania) jest istotnym wyzwaniem.
- Złożoność i koszty implementacji – wdrożenie systemu RAG wymaga zintegrowania kilku komponentów (baza wektorowa, retriever, LLM) i odpowiedniej infrastruktury. Może to generować dodatkowe koszty i wymagać specjalistycznej wiedzy.
- Latency (opóźnienia) – proces wyszukiwania informacji w bazie wiedzy dodaje dodatkowy krok przed generowaniem odpowiedzi, co może prowadzić do nieco dłuższego czasu odpowiedzi w porównaniu do użycia samego LLM. Optymalizacja pod kątem szybkości działania jest często konieczna.
- Ewaluacja i monitorowanie – ocena jakości działania systemu RAG jest bardziej złożona niż w przypadku standardowych LLM, ponieważ obejmuje zarówno ocenę jakości retrievalu, jak i generowanej odpowiedzi. Wymaga to opracowania odpowiednich metryk i procesów monitorowania. Obserwacja działania i publicznej recepcji systemów takich jak AI Overviews podkreśla złożoność ewaluacji i konieczność ciągłego monitorowania, zwłaszcza gdy system opiera się na dynamicznej i nie zawsze w pełni wiarygodnej bazie wiedzy, jaką jest internet.
- Obsługa złożonych zapytań – zapytania wymagające syntezy informacji z wielu różnych dokumentów lub fragmentów mogą stanowić wyzwanie dla obecnych mechanizmów RAG.
Zastosowania RAG w sztucznej inteligencji
Wszechstronność RAG (Retrieval-Augmented Generation) sprawia, że znajduje on zastosowanie w wielu obszarach wykorzystujących sztuczną inteligencję. Oto kilka przykładów:
- Zaawansowane chatboty i wirtualni asystenci – RAG pozwala tworzyć chatboty obsługi klienta, które odpowiadają na pytania w oparciu o aktualną ofertę, regulaminy czy dokumentację produktową. Wewnętrzne chatboty mogą pomagać pracownikom w szybkim odnajdywaniu informacji w firmowych bazach wiedzy.
- Inteligentne wyszukiwarki semantyczne – zamiast zwracać listę linków, wyszukiwarki oparte na RAG mogą dostarczać bezpośrednie, syntetyczne odpowiedzi na zadane pytania, opierając je na treściach znalezionych w zaindeksowanych dokumentach lub na stronach internetowych. Funkcje takie jak AI Overviews w wyszukiwarkach są publicznie widocznym przykładem tego kierunku, dążącym do bezpośredniego odpowiadania na zapytania.
- Systemy odpowiadania na pytania (Q&A) – RAG jest idealny do budowy systemów, które potrafią precyzyjnie odpowiadać na pytania dotyczące obszernej bazy dokumentów, np. prawnych, medycznych, technicznych czy naukowych.
- Generowanie treści opartych na danych – modele RAG mogą tworzyć raporty, podsumowania, analizy czy artykuły, bazując na dostarczonych danych źródłowych, co zapewnia ich faktograficzną poprawność.
- Systemy wspomagania decyzji – menedżerowie i analitycy mogą wykorzystywać RAG do szybkiego uzyskiwania wglądów i odpowiedzi opartych na wewnętrznych danych firmy, co wspiera podejmowanie świadomych decyzji biznesowych.
- Personalizacja w e-commerce – RAG może być używany do generowania spersonalizowanych rekomendacji produktów lub opisów, bazując na historii zakupów klienta i szczegółowych danych produktowych.
- Edukacja i badania – studenci i naukowcy mogą wykorzystywać RAG do szybkiego przeszukiwania i syntezy informacji z obszernych materiałów naukowych i edukacyjnych.
Przyszłość RAG w rozwoju AI
Technologia Retrieval-Augmented Generation jest dynamicznie rozwijającym się obszarem badań i wdrożeń w dziedzinie sztucznej inteligencji. Rosnące oczekiwania użytkowników, napędzane przez pojawienie się funkcji takich jak AI Overviews, stymulują badania nad ulepszaniem technik RAG, aby odpowiedzi były jeszcze bardziej trafne, wiarygodne i użyteczne. Przyszłość RAG rysuje się obiecująco, z kilkoma kluczowymi trendami i kierunkami rozwoju:
- Bardziej zaawansowane techniki retrievalu – oczekuje się rozwoju metod wyszukiwania, które będą lepiej radzić sobie ze złożonymi zapytaniami, syntezą informacji z wielu źródeł oraz rozumieniem kontekstu na głębszym poziomie. Może to obejmować hybrydowe podejścia łączące wyszukiwanie wektorowe z tradycyjnym wyszukiwaniem słów kluczowych.
- Integracja multimodalna – przyszłe systemy RAG będą prawdopodobnie zdolne do pracy nie tylko z tekstem, ale również z innymi typami danych, takimi jak obrazy, audio czy wideo, umożliwiając wyszukiwanie i generowanie odpowiedzi w oparciu o różnorodne źródła informacji.
- RAG w czasie rzeczywistym – usprawnienie mechanizmów indeksowania i aktualizacji baz wiedzy pozwoli na jeszcze szybsze reagowanie na zmiany w danych źródłowych, co jest kluczowe w zastosowaniach wymagających informacji w czasie rzeczywistym (np. analiza rynków finansowych, monitorowanie mediów).
- Adaptacyjne i samo-udoskonalające się RAG – rozwój technik pozwalających systemom RAG na uczenie się na podstawie interakcji z użytkownikiem i automatyczne dostosowywanie strategii retrievalu oraz generowania w celu poprawy jakości odpowiedzi.
- Optymalizacja kosztów i wydajności – dalsze prace nad optymalizacją algorytmów, modeli i infrastruktury RAG mają na celu zmniejszenie kosztów wdrożenia i utrzymania oraz skrócenie czasu odpowiedzi (latency).
- Lepsze mechanizmy ewaluacji i wyjaśnialności (Explainability) – rozwój narzędzi i metryk do dokładniejszej oceny działania systemów RAG oraz ulepszenie możliwości śledzenia, skąd pochodzą informacje wykorzystane do generowania odpowiedzi, co zwiększy zaufanie i transparentność. Wyzwania związane z dokładnością i wiarygodnością AI Overviews pokazują, jak ważny jest ten obszar.
RAG już teraz stanowi istotny element ekosystemu AI, a jego dalszy rozwój będzie prawdopodobnie kluczowy dla tworzenia coraz bardziej inteligentnych, wiarygodnych i użytecznych aplikacji opartych na dużych modelach językowych.
Czym jest RAG – najczęściej zadawane pytania
Czym jest Retrieval Augmented Generation?
Retrieval-Augmented Generation (RAG) to architektura sztucznej inteligencji, która łączy możliwości dużych modeli językowych (LLM) w zakresie generowania tekstu z zewnętrznym mechanizmem wyszukiwania informacji (retrieval). Zamiast polegać wyłącznie na wiedzy „zapamiętanej” podczas treningu, model RAG najpierw wyszukuje relewantne informacje w zewnętrznej bazie danych (np. dokumentach firmowych, artykułach), a następnie wykorzystuje je jako kontekst do wygenerowania bardziej dokładnej, aktualnej i opartej na faktach odpowiedzi.
Czym jest RAG w kontekście LLM?
W kontekście LLM, RAG jest techniką wzbogacania promptu (zapytania) kierowanego do modelu o dodatkowe informacje pobrane z zewnętrznego źródła. Dzięki temu LLM nie musi polegać tylko na swojej wewnętrznej wiedzy. Przykład: Wyobraźmy sobie chatbota bankowego opartego na RAG. Gdy klient pyta o oprocentowanie nowej lokaty, system RAG najpierw przeszukuje wewnętrzną bazę danych banku w poszukiwaniu aktualnych informacji o lokatach, a następnie przekazuje znalezione oprocentowanie i warunki do LLM wraz z oryginalnym pytaniem. LLM generuje odpowiedź, np.: „Aktualne oprocentowanie lokaty 'Super Zysk’ wynosi 5% w skali roku dla nowych środków na okres 6 miesięcy.”, bazując na świeżo pobranych, precyzyjnych danych, a nie na potencjalnie przestarzałej wiedzy z treningu. Podobny mechanizm, choć na znacznie większą skalę i oparty na zasobach internetu, można sobie wyobrazić za działaniem funkcji takich jak AI Overviews, które syntetyzują informacje znalezione w sieci.
Czy ChatGPT to RAG?Jaka jest koncepcja RAG?
Główną koncepcją RAG jest przezwyciężenie ograniczeń standardowych dużych modeli językowych (LLM), takich jak tendencja do generowania nieprawdziwych informacji (halucynacji) oraz brak dostępu do wiedzy aktualnej lub specyficznej dla danej dziedziny (np. danych firmowych). RAG realizuje to poprzez połączenie dwóch sił: zdolności LLM do płynnego generowania tekstu i rozumienia języka naturalnego oraz mocy systemów wyszukiwania informacji (information retrieval) do odnajdywania precyzyjnych danych w dużych zbiorach. W skrócie, RAG „uziemia” generatywne możliwości LLM w konkretnych, weryfikowalnych faktach, dostarczając mu odpowiedni kontekst „na żądanie” przed wygenerowaniem odpowiedzi.